第5章 数据的导入与导出
到目前为止,我们已经学会了如何使用SQL的INSERT语句向表中添加少量行。对于制作临时测试表或者向已有表添加少量行来说,这种逐行插入是很有用的。但是当你需要加载数百行、数千行甚至数百万行的时候,你肯定不愿意再一个接一个地编写单独的INSERT语句。好在我们有更好的办法可以处理这种情况。
如果你的数据储存在带有分隔符的文本里面,其中每个文本行都是一个表行,并且行中每个列的值都使用逗号或者其他字符进行分隔,那么PostgreSQL就可以通过COPY命令批量导入数据。这个命令是PostgreSQL特有的实现,它提供了一些选项,可以让我们包含或者排除特定列并处理不同种类的分隔符文本。
反过来说,COPY也可以将PostgreSQL的表或者查询结果导出至带有分隔符的文本文件。当你需要和同事分享数据,又或者需要将数据转换为诸如Excel文件等其他格式时,这种技术将会相当方便。
本书在第4章的“了解字符”一节曾经简要地介绍了COPY的导出用法,本章将对这个命令的导入和导出用法作更加深入的介绍。对于导入,我们将以美国年度人口普查的县级人口估算开始,这是我个人最喜欢的数据集之一。
大部分导入工作可以归纳为以下三个步骤:
以带有分隔符的文本文件形式提供源数据。
创建储存数据的表。
编写执行导入工作的
COPY语句。
完成导入之后,我们将会检查数据,并学习更多导入和导出的相关选项。
在专有和开源的系统之间迁移数据时,最常见的文件格式就是带有分隔符的文本文件,这也是我们着重讨论这种文件类型的原因。如果你想把数据从另一个数据库程序的专有格式直接传输至PostgreSQL,比如将Microsoft Access或者MySQL的数据传输至PostgreSQL,那么就需要使用第三方工具。请查看PostgreSQL的维基网站 https://wiki.postgresql.org/wiki/ ,并搜索“从其他数据库转换至PostgreSQL”以获取相关的工具和选项。
如果你是通过其他数据库管理器在使用SQL,那么请查阅该数据库的文档以了解它是如何处理批量导入的。比如说,MySQL数据库使用就的是LOAD DATA INFILE语句,而微软的SQL Server使用的则是它自有的BULK INSERT命令。
处理带有分隔符的文本文件
很多软件应用都以独特的格式储存数据,将这类数据格式翻译成另一种数据格式并不是一件容易的事,就像只会英文的人硬要读懂汉字一样。好在很多软件都可以导入或者导出为带分隔符的文本文件, 这是一种常见的数据格式,可以作为一种中间地带。
带有分隔符的文本文件由数据行组成,每个数据行代表表中的一个行,行中的每个数据列由特定的字符分隔,或者说划定界限。我见过各式各样用作分隔符的字符,从安培符号到管道符号都有,但逗号是最常用的;因此你会经常看到被称为逗号分隔值(CSV)的文件类型。CSV和逗号分隔在术语上是等价的。
以下是一个你可能在逗号分隔文件里面看到的典型数据行:
John,Doe,123 Main St.,Hyde Park,NY,845-555-1212请注意,包括名字、姓氏、街道、镇、洲和电话在内,数据的每个部分都被逗号隔开,没有用到任何空格。逗号会告知软件在导入或者导出时将每个项用作一个单独的列。简单直接。
处理标题行
带有分隔符的文本文件的其中一个特点就是带有标题行。顾名思义,它就是顶部或者首部的一个行,里面列出了每个数据列的名字。通常情况下,这些标题是在数据库或者电子表格导出数据时添加的。下面是一个我一直使用的带有分隔符的行示例。标题行中的每一项都与相应的列对应:
xxxxxxxxxxFIRSTNAME,LASTNAME,STREET,CITY,STATE,PHONEJohn,Doe,123 Main St.,Hyde Park,NY,845-555-1212标题行有好几个作用。首先,标题行中的值标识了每一列的数据,它对于解读文件内容非常有用。其次,PostgreSQL以外的某些数据库管理器会通过标题行,将文件的列映射至导入表的正确列上。因为PostgreSQL不使用标题行,所以我们也不会把这种行导入至表中。为此我们需要使用COPY命令的HEADER选项来排除它们。接下来的一节将对COPY的所有选项进行介绍。
引用包含分隔符的列
使用逗号作为列的分隔符会导致一个潜在的问题:如果列中的值包含逗号,那该怎么办呢?举个例子,有时候人们会把公寓号码和街道地址结合起来,比如123 Main St., Apartment 200。如果分隔系统无法把这个额外的逗号处理好,那么在导入的过程中这一行就会出现一个额外的列并导致导入失败。
为了处理这种情况,带有分隔符的文件会使用一个任意的字符来包围含有分隔符的列,这个字符被称为文本限定符。文本限定符可以作为一个信号,忽略分隔符并将文本限定符之间的所有内容看作一个单独的列。在大多数情况下,逗号分隔文件都会使用双引号作为文本限定符。下面是同样的示例数据,但是街道名称一栏使用了双引号进行包围:
xxxxxxxxxxFIRSTNAME,LASTNAME,STREET,CITY,STATE,PHONEJohn,Doe,"123 Main St., Apartment 200",Hyde Park,NY,845-555-1212在导入时,数据库将把双引号包围的内容看作一列,无论其内部是否包含分隔符。在导入CSV文件时,PostgreSQL默认会忽略双引号列中的分隔符,但如果你有需要的话,也可以在导入时指定一个不同的文本限定符。(考虑到IT从业人员有时候会遇到一些奇怪的需求,你可能确实会需要采用不同的字符。)
最后,在CSV模式下,如果PostgreSQL在一个双引号列里面发现了两个连续的文本限定符,那么它会把其中一个删掉。举个例子,如果PostgreSQL发现了这样的数据:
xxxxxxxxxx"123 Main St."" Apartment 200"
那么它在导入时将把这段文本看作单独的列,只保留其中一个限定符:
xxxxxxxxxx123 Main St." Apartment 200
出现这种情况意味着你的CSV文件可能存在格式错误,正如我们之后看到的例子所示,在导入数据之后最好再检查一下数据。
使用COPY导入数据
为了将外部文件中的数据导入至数据库,我们首先需要在数据库创建一个表,并且该表的列和数据类型必须与源文件匹配。在此之后,我们只需要执行代码清单5-1中的三行代码,就能够用COPY语句完成导入工作了。
xxxxxxxxxx➊ COPY table_name➋ FROM 'C:\YourDirectory\your_file.csv'➌ WITH (FORMAT CSV, HEADER);代码清单5-1:使用COPY导入数据
上述代码块以COPY关键字➊开头,后面跟着目标表的名字,并且这个表必须已经存在于数据库中。你可以把这句代码看作是“将数据复制至名为table_name的表中”。
接下来的FORM关键字➋确定了源文件的完整路径,它被包围在单引号里面。指定路径的方法取决于你的操作系统。对于Windows,它的路径将以盘符、冒号、反斜线和目录名为开始。比如说,为了导入我Windows桌面上的一个文件,需要用到以下FROM代码行:
xxxxxxxxxxFROM 'C:\Users\Anthony\Desktop\my_file.csv'而在macOS和Linux上,路径则以带有正斜线的根目录为开始一路延续下去。当我想要导入位于macOS桌面的一个文件时,FROM代码行可能会是这样的:
xxxxxxxxxxFROM '/Users/anthony/Desktop/my_file.csv'对于书中展示的例子,我将使用Windows风格的路径C:\YourDirectory\作为占位符。你需要将这个占位符替换为你从GitHub下载的CSV文件的储存路径。
最后的WITH关键字➌可以让我们指定相应的选项,这些选项被括号包围,用于调整输入或者输出文件。在这个例子中,我们指定外部文件应该使用逗号进行分隔,并且在导入时无需包含标题行。PostgreSQL的官方文档https://www.postgresql.org/docs/current/sql-copy.html列出了所有可选项,有时间的话可以去了解一下,而以下则是一些经常会用到的选项:
输入和输出文件的格式
FORMAT format_name选项用于指定你想要读写的文件类型。其中的格式名字可以是CSV、TEXT或者BINARY。除非你正在深入地构建技术系统,否则你很少需要用到BINARY格式,这种格式会将数据储存为字节序列。在大部分情况下,与我们打交道的都是标准的CSV文件。至于TEXT格式,它在默认情况下将使用制表符作为分隔符,你也可以指定其他字符作为分隔符,而反斜线字符则会被识别为它们的ASCII等价物,比如\r就会被设别为回车。TEXT格式主要用于PostgreSQL内置的备份程序。
决定标题行的去留
在导入时,可以使用HEADER来指明你想要排除源文件中的标题行。数据库将从文件的第二行开始导入,这样标题中的列名就不会成为表中数据的一部分。(请检查源CSV文件以确保这是你想要的行为,并不是每个CSV文件都拥有标题行!)。在导出时,可以使用HEADER告知数据库你想要在输出文件中包含列名作为标题行,这对于用户了解文件内容会有所帮助。
分隔符
DELIMITER 'character'选项可以让你在导入或者导出文件时指定某个字符作为分隔符。分隔符必须是单个字符,不能是回车。如果你使用FORMAT CSV格式,那么分隔符将默认为逗号。DELIMITER选项的存在使得我们可以通过指定不同的分隔符来处理不同的数据。比如说,如果你接收到的是用管道符号分隔的数据,那么你可以使用DELIMITER '|'选项来处理它。
引号
稍早之前的内容曾经提到过,在CSV文件中,如果单个列的值中包含逗号,那么除非你使用一组被用作文本限定符的字符去包裹它们,否则导入进程将会被扰乱。在默认情况下,PostgreSQL使用双引号作为文本限定符,但如果你要导入的CSV使用了不同的字符作为文本限定符,那么你可以使用QUOTE 'quote_character'选项来指定它。
在更好地理解带有分隔符的文件之后,现在是时候开始进行实际的导入工作了。
导入县的人口普查数据
这个导入练习要处理的数据集比之前第2章接触过的教师表要大得多。它包含了美国每个县的人口普查估算数据,共有3,142行,每行有16个列。(普查涉及的县还包含一些拥有其他名字的地理区域:路易斯安那州的教区,阿拉斯加的自治市镇和人口普查区域,还有一些城市,特别是弗吉尼亚州的城市。)
为了更好地了解数据,我们需要知道一些关于美国人口普查局的信息,它是一个跟踪美国人口统计数据的联邦机构。该机构最著名的项目是每10年对人口进行一次全面统计,最近一次统计是在2020年。这些数据列举了美国每个人的年龄、性别、种族和族裔,用于确定由435名成员组成的美国众议院中每个州的成员数量。最近几十年,得克萨斯州和佛罗里达州等增长较快的州获得了更多席位,而增长较慢的州如纽约州和俄亥俄州在众议院的代表则减少了。
我们将要使用的数据是人口普查的年度人口估算数据。这些数据以最近10年的人口普查数据为基准,并将出生、死亡、国内和国际移民等因素考虑在内,从而得出每年全国、各州、各县和其他地区的人口估算值。跟每年执行实际的计数相比,这是一种估算全美各地最新居住人口数量的最佳方式。在这个练习中,我将2019年美国人口普查县级人口估算值中的一些列(还有人口普查地理数据中的一些描述性列)编入一个名为us_counties_pop_est_2019.csv的文件。如果你完成了第1章“从GitHub下载代码和数据”一节中的指示,那么你的电脑里应该会有这个文件。如果没有的话,那么请现在就去下载它。
注意
曾经的瓦尔迪兹-科尔多瓦人口普查区域在2019年被拆分成了阿拉斯加州两个新的人口普查区域,这一变化使得美国的县数量增加到了3,143个,但本练习所使用的2019年人口估算数据并未反映这一点。
使用文本编辑器打开上述文件,你将会看到一个标题行,它包含了以下这些列:
xxxxxxxxxxstate_fips,county_fips,region,state_name,county_name, --snip--接下来,我们将检查创建导入表的代码并探索这些列。
创建 us_counties_pop_est_2019 表
代码清单5-2展示了CREATE TABLE脚本。在pgAdmin中点击我们在第2章创建的analysis数据库。(最好将本书中的数据都储存在analysis数据库里面,以便在之后的章节中复用其中的一些数据。)从pgAdmin的菜单栏中选择工具 ▸ 查询工具。你可以直接把代码键入至查询工具中,又或者从你在GitHub下载的文件里面复制代码。请把脚本代码放置到查询工具窗口里面,然后运行它们。
xxxxxxxxxxCREATE TABLE us_counties_pop_est_2019 ( ➊ state_fips text, county_fips text, ➋ region smallint, ➌ state_name text, county_name text, ➍ area_land bigint, area_water bigint, ➎ internal_point_lat numeric(10,7), internal_point_lon numeric(10,7), ➏ pop_est_2018 integer, pop_est_2019 integer, births_2019 integer, deaths_2019 integer, international_migr_2019 integer, domestic_migr_2019 integer, residual_2019 integer, ➐ CONSTRAINT counties_2019_key PRIMARY KEY (state_fips, county_fips));代码清单 5-2 :用于县级人口普查估算的CREATE TABLE语句
之后回到pgAdmin主窗口,在对象浏览器中右键点击并刷新analysis数据库。选择策略 ▸ 公开 ▸ 表以查看新创建的表。尽管该表目前还是空无一物,但你还是可以通过在pgAdmin的查询工具里面执行基本的SELECT查询来查看它的结构:
xxxxxxxxxxSELECT * FROM us_counties_pop_est_2019;执行这个SELECT查询之后,你将在pgAdmin的数据输出方框中看到刚刚创建的表及其各个列。接下来,我们将通过导入数据,向这个空白表插入行。
了解人口普查列及其数据类型
在将CSV文件导入表之前,让我们先来看看代码清单5-2中选择的列和数据类型。我使用了两个官方的人口普查数据字典作为指南:一个用于估算(https://www2.census.gov/programs-surveys/decennial/rdo/about/2010-census-programs/2010Census_pl94-171_techdoc.pdf),而另一个则用于每十年一次的统计,并且统计中包含地理列(http://www.census.gov/prod/cen2010/doc/pl94-171.pdf)。我还在表格定义中为某些列取了一个更易懂的名字。尽可能地依靠数据字典是一个非常好的做法,因为它可以帮助你避免错误地配置列或者潜在的数据丢失。一定要想方设法获取这样的字典,如果数据是公开的,那么请进行相应的在线搜索。
在这组人口普查数据中,还有你刚刚创建的表中,每一个行都显示了一个县的人口估算值以及每年产生变化的部分:出生、死亡和迁移。前两列是该县的state_fips ➊和county_fips,它们是这些实体的标准联邦代码。我们之所以使用文本表示这两列,是因为这些代码可能包含前置的零,如果我们将这些值储存为整数,那么这些零可能会丢失。比如说,阿拉斯加的state_fips是02,但如果我们使用整数类型储存这个数字,那么在导入时它前置的0将会被剥离,只剩下2,这并不是该州的正确代码。此外,我们不需要对这个值做任何数学运算,所以不需要用到整数。区分代号和数字总是非常重要的;这些州和县的值实际上是标签,而不是用于数学计算的数字。
region➋使用数字1至4来表示一个县在美国的一般位置:东北部、中西部、南部或者西部。因为用到的数字不会超过4,所以这一列被定义为smallint类型。至于state_name ➋和county_name两列则分别包含了州和县的完整名称,它们以文本形式储存。
县的土地和水体面积分别记录在area_land➍和area_water中,两者相加则构成了县的总面积。在类似如阿拉斯加这样拥有大量土地和积雪的地方,它们的某些数值很可能会超过integer类型的最大值2,147,483,647。考虑到这一点,我们使用了bigint类型,这种类型即使是在处理育空-科尤库克人口普查区377,038,836,685平方米的土地时也是绰绰有余的。
接近县中心位置的地方被称为内部点,它们的纬度和经度分别通过internal_point_lat和internal_point_lon➎指定。人口普查局和很多地图系统一样,都使用十进制度数系统表示经纬度坐标。纬度代表地球上的南北位置,赤道为0度,北极为90度,南极为-90度。
经度代表东西方向的位置,其中经过伦敦格林尼治的本初子午线的经度为 0 度。从那里开始,经度向东西两个方向增长(正数向东而负数则向西),直到它们在地球另一侧180度处相遇。那个位置也被称为对角线,它是国际日期变更线的基础。
人口普查局在报告内部点时最多使用7位小数。对于小数点左边不会超过180的这个值,我们总共最多需要核算10位数字。因此我们将使用精度为10而刻度为7的numeric类型。
注意
PostgreSQL可以通过PostGIS扩展储存几何数据,这种数据可以在单个列中包含代表纬度和经度的点。本书将在第15章的地理查询中探讨几何数据。
再下来,我们会看到一连串的列➏,它们包含了该县的人口估算值以及各个产生变化的部分。表5-1列出了这些列的定义。
表5-1:人口普查人口估算列
| 列名 | 描述 |
|---|---|
pop_est_2018 | 2018年7月1日的估算人口 |
pop_est_2019 | 2019年7月1日的估算人口 |
births_2019 | 2018年7月1日至2019年6月30日的出生人数 |
deaths_2019 | 2018年7月1日至2019年6月30日的死亡人数 |
international_migr_2019 | 2018年7月1日至2019年6月30日的净国际移民人数 |
domestic_migr_2019 | 2018年7月1日到2019年6月30日的国内净移民人数 |
residual_2019 | 用于调整估算值以保持一致的数字 |
最后,CREATE TABLE语句以CONSTRAINT子句➐结束,该子句指定state_fips和county_fips作为该表的主键。这意味着这些列的组合对于该表中的每一条记录都是唯一的,这个概念我们将在第8章中进行更广泛讨论。现在,让我们先来执行导入操作。
使用COPY导入人口普查数据
我们已经完成将人口普查数据导入表前的所有准备,接下来要做的就是运行代码清单5-3中的代码(别忘了把里面的路径修改成数据在你电脑上的位置):
xxxxxxxxxxCOPY us_counties_pop_est_2019FROM 'C:\YourDirectory\us_counties_pop_est_2019.csv'WITH (FORMAT CSV, HEADER);代码清单5-3:使用COPY导入人口普查数据
代码执行完毕之后,你应该会在pgAdmin看到以下信息:
xxxxxxxxxxCOPY 3142Query returned successfully in 75 msec.
这是一条好消息:它表明被导入的行数量跟CSV的行数量一致。如果你给定的源CSV或者导入语句出了问题,那么数据库将抛出一个错误。举个例子,如果CSV中某一行的列数量多于目标表中的列数量,那么你将在pgAdmin的数据输出方框看到一条错误信息,提示你错误的修复方法:
xxxxxxxxxxERROR: extra data after last expected columnContext: COPY us_counties_pop_est_2019, line 2: "01,001,3,Alabama, ..."
另一方面,即使数据库没有报告错误,我们也应该目测一下刚刚导入的数据,从而确保一切符合预期。
检查导入的数据
首先,使用一个SELECT查询来获取所有列和行:
xxxxxxxxxxSELECT * FROM us_counties_pop_est_2019;如果一切正常,那么pgAdmin应该会打印出3,142行,并且当你在结果集中左右滚动的时候,每一列都应该拥有预期的值。让我们来回顾一下其中的某些行,毕竟当初为了给它们定义合适的数据类型可是费了我们不少功夫。举个例子,运行接下来的查询将展示拥有最大area_land值的一些县。查询中用到的LIMIT子句将限制查询返回的行数量,在这个例子中,查询最多只会返回三个行:
xxxxxxxxxxSELECT county_name, state_name, area_landFROM us_counties_pop_est_2019ORDER BY area_land DESCLIMIT 3;这个查询会以平方米为单位,将县级别的地理区域按面积从大到小排序。正如之前所说,由于该字段的最大值超过了普通integer类型提供的最大值,所以area_land被定义成了bigint类型。正如我们所料,广袤的阿拉斯加地理区域出现在了结果的前列:
xxxxxxxxxxcounty_name state_name area_land------------------------- ---------- ------------Yukon-Koyukuk Census Area Alaska 377038836685North Slope Borough Alaska 230054247231Bethel Census Area Alaska 105232821617接下来,让我们检查一下使用numeric(10,7)定义的纬度列和经度列,也即是internal_point_lat列和internal_point_lon列。这段代码将按经度从大到小排序各县,并且使用LIMIT子句检索前5行:
xxxxxxxxxxSELECT county_name, state_name, internal_point_lat, internal_point_lonFROM us_counties_pop_est_2019ORDER BY internal_point_lon DESCLIMIT 5;经度衡量的是自东向西的位置,其中英国本初子午线以西的位置用负数表示,从-1、-2、-3开始,以此类推,越往西越远。因为代码使用了降序排序,所以美国最东边的县将出现在查询结果的最前面。这个结果最令人出乎意料的,可能就是孤单的阿拉斯加地区出现在了顶部:
xxxxxxxxxxcounty_name state_name internal_point_lat internal_point_lon-------------------------- ---------- ------------------ ------------------Aleutians West Census Area Alaska 51.9489640 179.6211882Washington County Maine 44.9670088 -67.6093542Hancock County Maine 44.5649063 -68.3707034Aroostook County Maine 46.7091929 -68.6124095Penobscot County Maine 45.4092843 -68.6666160原因是这样的:阿拉斯加的阿留申群岛向西延伸得很远(它们的位置比夏威夷更西),以至于在180度经度上穿过了对角线。不过好在这并不是数据错误,而是一个事实,你可以把这个小知识点记下来,留待以后在团队小知识竞赛时使用。
恭喜!现在你的数据库拥有了一套合法的政府人口数据。我们将在本章后面用它来演示如何用COPY导出数据,并在第6章使用它学习数学函数。不过在学习如何导出数据之前,让我们先来研究一些额外的导入技术。
使用COPY导入部分列
即使CSV文件没有包含目标数据库表的所有列,我们仍然可以通过指定数据中存在的列来导入现有的数据。考虑这样一种场景:你正在研究你所在州所有镇主管的薪资,以便按地域分析政府的支出趋势。为此,你首先需要使用代码清单5-4中的代码,创建一个名为supervisor_salaries的表。
xxxxxxxxxxCREATE TABLE supervisor_salaries ( id integer GENERATED ALWAYS AS IDENTITY PRIMARY KEY, town text, county text, supervisor text, start_date date, salary numeric(10,2), benefits numeric(10,2));代码清单5-4:创建表以追踪主管的薪资
这段代码创建了一个包含多个列的表,其中包括自动递增的、作为主键的id列,还有镇名、县名和主管名称,这些主管开始履职的日期以及他们的薪资和福利。但是当你尝试跟县的第一书记联系的时候,他却说自己只有镇名、主管名称和薪资这三项信息,而其余信息则需要从其他地方获取。你只好请他将现有的数据都放到CSV文件里面,而自己则尽可能地导入这些数据。
本书已经包含了一个类似的CSV样本,名为supervisor_salaries.csv,你可以在本书的资源网站下载它:https://www.nostarch.com/practical-sql-2nd-edition/。如果你使用文本编辑器查看该文件,那么你应该会在顶部看到以下这两行文字:
xxxxxxxxxxtown,supervisor,salaryAnytown,Jones,67000我们可以尝试用基本的COPY语法导入它:
xxxxxxxxxxCOPY supervisor_salariesFROM 'C:\YourDirectory\supervisor_salaries.csv'WITH (FORMAT CSV, HEADER);但这样做只会让PostgreSQL向我们返回一个错误:
xxxxxxxxxxERROR: invalid input syntax for type integer: "Anytown"Context: COPY supervisor_salaries, line 2, column id: "Anytown"SQL state: 22P04问题在于表的第一列是自动递增的id,但被导入的CSV文件却是以文本列town为开始。退一步来说,即使CSV文件的第一列是整数,GENERATED ALWAYS AS IDENTITY关键字也会阻止我们为id列赋值。为了解决这个问题,我们需要像代码清单5-5那样,向数据库告知CSV中存在表的哪些列。
xxxxxxxxxxCOPY supervisor_salaries ➊ (town, supervisor, salary)FROM 'C:\YourDirectory\supervisor_salaries.csv'WITH (FORMAT CSV, HEADER);代码清单5-5:将CSV中薪资等相关数据导入至表的三个列中
通过在表名之后用括号➊指出业已存在的三个列,我们告知PostgreSQL:在读取CSV的时候,只需要查找填充这三个列的数据即可。现在,如果我们再次获取表的前几行,那么就会看到这些列已经被填充了适当的值:
xxxxxxxxxxid town county supervisor start_date salary benefits-- -------- ------ ---------- ---------- ---------- --------1 Anytown Jones 67000.002 Bumblyburg Larry 74999.00
使用COPY导入部分行
PostgreSQL从12版开始,允许在COPY语句中通过添加WHERE子句来过滤从CSV导入至表的行。我们可以通过主管薪资数据来演示这一操作。
首先,我们需要通过DELETE查询,将前面导入到supervisor_salaries表的所有数据全部删除。
xxxxxxxxxxDELETE FROM supervisor_salaries;上述操作将从表中移除所有数据,但是不会重置id列的IDENTITY列序列(column sequence)。本书第8章在讨论表设计的时候会介绍如何做到这一点。在删除操作完成之后,请运行代码清单5-6中的COPY语句,这条语句添加了一个WHERE子句用于过滤被导入的CSV行:仅在一个行的town列与New Brillig相匹配时,它才会被导入。
xxxxxxxxxxCOPY supervisor_salaries (town, supervisor, salary)FROM 'C:\YourDirectory\supervisor_salaries.csv'WITH (FORMAT CSV, HEADER)WHERE town = 'New Brillig';代码清单5-6:使用WHERE导入部分行
之后,执行SELECT * FROM supervisor_salaries;以观察表当前包含的内容,我们应该只会看到以下这一行:
xxxxxxxxxxid town county supervisor start_date salary benefits-- ----------- ------ ---------- ---------- --------- --------10 New Brillig Carroll 102690.00这种只导入部分行的做法使用起来非常方便。下面,让我们来了解一下,如何使用临时表在导入过程中进行更多数据处理。
在导入过程中向列添加值
如果你导入的CSV文件缺少县的名字,但你却知道该列的值实际上为“Mills”,这时你该怎么办呢?改变导入操作使其包含县名的其中一种方法,就是先将CSV导入至临时表,然后修改临时表中的数据,最后再将修改后的数据导入至supervisors_salary表。临时表只会在数据库会话期间存在——每当我们重新打开数据库又或者断开数据库连接时,它就会消失。由于这种特性,临时表非常适合在处理流程中对数据进行中间操作。
请再次使用DELETE查询清空之前导入至supervisor_salaries表的数据。清理操作完成之后,运行代码清单5-7中的代码,它会创建一个临时表并将CSV导入其中。之后,我们将从临时表中查询数据,并将县名以及其他数据一并插入至supervisor_salaries表中。
xxxxxxxxxx➊CREATE TEMPORARY TABLE supervisor_salaries_temp (LIKE supervisor_salaries INCLUDING ALL); ➋COPY supervisor_salaries_temp (town, supervisor, salary) FROM 'C:\YourDirectory\supervisor_salaries.csv' WITH (FORMAT CSV, HEADER); ➌INSERT INTO supervisor_salaries (town, county, supervisor, salary) SELECT town, 'Mills', supervisor, salary FROM supervisor_salaries_temp; ➍DROP TABLE supervisor_salaries_temp;代码清单5-7:在导入过程中使用临时表为某个列添加默认值
这个脚本执行了四个任务。首先,通过将原始表supervisor_salaries的名字传递给LIKE关键字作为参数,在supervisor_salaries表的基础上创建了一个名为supervisor_salaries_temp➊的临时表。至于INCLUDING ALL关键字则告知PostgreSQL不仅要复制表的行和列,还要复制索引和IDENTITY设置等组件。然后再使用我们现已熟知的COPY语法,将supervisor_salaries.csv文件➋导入至临时表中。
之后,脚本使用了INSERT语句➌来填充薪资表。这个查询指定被单引号包围的字符串Mills作为第二列的值,而不是作为列名,至于其他列的数据则通过使用SELECT查找临时表来获取。
最后,在导入操作完成之后,脚本使用DROP TABLE删除临时表➍。临时表在PostgreSQL连接断开时也会自动消失,现在删除它主要是为了之后可能出现的同类导入提供崭新的临时表。
上述脚本执行完毕之后,我们可以运行SELECT语句来获取表的前几个行以观察脚本产生的效果:
xxxxxxxxxxid town county supervisor start_date salary benefits-- -------- --------- ---------- ---------- --------- --------11 Anytown Mills Jones 67000.0012 Bumblyburg Mills Larry 74999.00可以看到,county字段现在已经填充了值,尽管该值并不存在于源CSV中。虽然这次导入看上去并不轻松,但它却揭示了如何在数据处理过程中通过多个步骤来获得期望的结果,因此它是相当具有教育意义的,并且这个临时表演示也足以说明SQL在控制数据处理方面的灵活性。
使用COPY导出数据
在使用COPY导出数据的时候,我们不再使用FROM指示源数据,而是使用TO指示输出文件的路径和名字,并且导出的数据量也是可以控制的:可以是整个表,也可以是寥寥几列,又或者是某个查询的结果。
让我们来看看几个简单的例子。
导出所有数据
最简单的导出方式就是将表中的所有数据都发送至一个文件。稍早之前,我们创建了us_counties_pop_est_2019表,它拥有16列和3,142行的人口普查数据,而代码清单5-8中的SQL语句则把该表中的所有数据都导出至名为us_counties_export.txt的文本文件中。为了展示灵活多变的输出可选项,代码通过WITH关键字告知PostgreSQL需要将标题行包含在输出之内,并且使用管道符号而不是逗号作为分隔符。 这里使用.txt作为文件的扩展名有两个原因:首先,这表名我们可以使用除.csv以外的其他名字作为文件的扩展名;其次,因为这个文件使用管道符号而不是逗号作为分隔符,所以我想避免将文件称为.csv,除非它真的使用逗号作为分隔符。
别忘了将代码中的输出目录改为你实际的保存位置。
xxxxxxxxxxCOPY us_counties_pop_est_2019TO 'C:\YourDirectory\us_counties_export.txt'WITH (FORMAT CSV, HEADER, DELIMITER '|');代码清单5-8:使用COPY导出整个表
使用文本编辑器打开被导出的文件,我们将看到以下格式的数据(此处展示的是截断后的结果):
xxxxxxxxxxstate_fips|county_fips|region|state_name|county_name| --snip--01|001|3|Alabama|Autauga County --snip--这个文件包含一个由列名组成的标题行,并且所有列都以管道符号隔开。
导出特定列
有时候我们并不需要或者并不想要导出所有数据:数据中可能包含敏感信息,比如社会安全号码或者出生日期,需要保护隐私。具体来说,以人口普查数据为例,一个制图程序可能只需要县名和地理坐标就可以绘制出县的位置。正如代码清单5-9所示,如果我们只想要导出三个列,那么只需要在表名后面的括号中列出它们即可。当然,你必须准确地输入数据中出现的列名,这样PostgreSQL才能够识别它们。
xxxxxxxxxxCOPY us_counties_pop_est_2019 (county_name, internal_point_lat, internal_point_lon)TO 'C:\YourDirectory\us_counties_latlon_export.txt'WITH (FORMAT CSV, HEADER, DELIMITER '|');代码清单5-9:使用COPY导出表中的指定列
导出查询结果
除了上面展示的两种导出之外,我们还可以通过在COPY中使用查询来微调导出结果。通过使用第3章“同时使用WHERE和LIKE/ILIKE”一节中介绍的不区分大小写的ILIKE和%通配符,代码清单5-10导出了名称中包含mill的县以及该县所属的州,无论这些县名的大小写情况如何。另外需要注意的是,因为这个例子没有在WITH子句中使用DELIMITER关键字,所以导出结果将是默认的逗号分隔值。
xxxxxxxxxxCOPY ( SELECT county_name, state_name FROM us_counties_pop_est_2019 WHERE county_name ILIKE '%mill%' )TO 'C:\YourDirectory\us_counties_mill_export.csv'WITH (FORMAT CSV, HEADER);代码清单5-10:使用COPY导出查询结果
运行上述代码之后,它将输出一个包含9个行的文件,其中包含了Miller、Roger Mills和Vermillion等县名:
xxxxxxxxxxcounty_name,state_nameMiller County,ArkansasMiller County,GeorgiaVermillion County,Indiana--snip--
使用pgAdmin进行导入和导出
SQL的COPY命令有时候无法处理某些导入和导出。在连接远程电脑的PostgreSQL实例时,通常就会出现这种情况,其中一个例子就是连接亚马逊网络服务(AWS)等云计算环境中的机器。在那种环境下,PostgreSQL只会寻找位于远程机器中的文件和文件路径,但是却无法在本地计算机中查找文件。为了使用COPY,你需要把本地数据转移至远程服务器,但你可能并没有这样做的权利。
解决这个问题的一个变通的方法,就是使用pgAdmin内建的导入/导出向导。首先,在pgAdmin左侧垂直方框的对象浏览器中,通过选择数据库(Databases) ▸ analysis ▸ 模式(Schemas) ▸ 表(Tables),找到你在analysis数据库中的表。
接下来,右键点击你想要导入或者导出的表,并选择导入/导出(Import/Export)。之后会出现一个如图5-1所示的对话框,让你选择如何对表实施导入或导出。
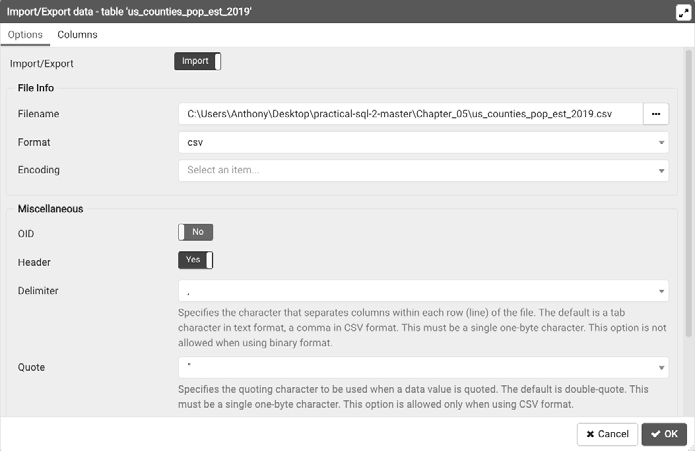 图5-1:pgAdmin的导入/导出对话框
图5-1:pgAdmin的导入/导出对话框
为了执行导入操作,我们需要将导入/导出滑块移动至导入(Import)。首先,点击文件名(Filename)框体右边的三个小点,找到你的CSV文件。然后,从格式(Format)下拉列表中选择csv。再然后,根据需要调整标题、分隔符、引号和其他选项。最后点击确定(OK),导入数据。
如果要执行的是导出操作,那么请使用相同的对话框并遵循类似的步骤。
之后的第18章在讨论通过计算机命令行使用PostgreSQL的时候,我们将探索另一种方法来完成导入和导出任务,其中将用到psql工具以及它的\copy命令。pgAdmin的导入/导出向导实际上就在后台使用\copy,只是为其提供了一个更友好的界面。
小结
现在你已经学会了如何将外部数据引入数据库,你可以开始挖掘各式各样的数据集:无论是成千上万的公开数据集,还是与你职业或研究相关的数据。很多数据都以CSV格式或者易于转换为CSV的格式提供。你还可以寻找数据字典来帮助你理解数据,并为每个字段选择正确的数据类型。
作为本章练习的一部分,我们导入的人口普查数据将在下一章探讨SQL的数学函数时发挥重要作用。
实战演练
你可以通过以下练习继续探索数据的导入和导出。别忘了查阅PostgreSQL的文档以获得提示:https://www.postgresql.org/docs/current/sql-copy.html 。
请编写一个带有
WITH关键字的COPY语句,用于导入一个假想的文件,它的前几行为以下形式:xxxxxxxxxxid:movie:actor50:#Mission: Impossible#:Tom Cruise使用你在本章中创建并填充的
us_counties_pop_est_2019表,将美国出生人口最多的20个县导出至CSV文件。请确保只有每个县的名称、州和出生人数会被导出。(提示:每个县的出生人数都汇总在births_2019一栏中。)假设你现在正在导入一个文件,其中一列包含了以下这些值:
xxxxxxxxxx17519.66820084.46118976.335在你的目标表中,数据类型为
numeric(3,8)的列对这些值是否有效?原因是什么?