第1章 Go与Web应用¶
本章将介绍以下内容
Web 应用的定义
使用 Go 编写 Web 应用的优点
Web 应用编程的基本知识
使用 Go 编写一个极为简单的 Web 应用
Web应用在我们的生活中无处不在。看看我们日常使用的各个应用程序,它们要么就是Web应用,要么就是移动App这类Web应用的变种。无论哪一种编程语言,只要它能够开发出与人类进行交互的软件,那么它就必然会支持Web应用开发。对于一门崭新的编程语言来说,它的开发者首先要做的其中一件事,就是构建与互联网(internet)和万维网(World Wide Web)进行交互的库(library)以及框架,而那些更为成熟的编程语言还会有各种五花八门的Web开发工具。
Go是一门刚开始崭露头角的语言,它是为了让人们能够简单且高效地编写后端系统(back end system)而创建的。这门语言拥有众多先进的特性,并且密切关注程序员的生产力以及各种与速度相关的事项。和其他语言一样,Go也提供了对Web编程的支持。自从Go面世以来,它在编写Web应用以及“X即服务类系统”(*-as-a-service system)方面就受到了大家的热烈追捧。
本章接下来将列举一些使用Go编写Web应用的优点,并介绍一些关于Web应用的基本知识。
1.1 使用Go语言构建Web应用¶
“为什么要使用Go来编写Web应用呢?”作为本书的读者,我想你肯定很想知道这个问题的答案。本书是一本教授人们如何使用Go进行Web编程的图书,而作为本书的作者,我的任务就是向您解释为什么人们会使用Go进行Web编程,以及这样做的理由是什么。本书将在接下来的内容中陆续介绍Go在Web开发方面的优点,我衷心地希望您也能够对这些优点有感同身受的想法。
Go是一门相对比较年轻的编程语言,它拥有繁荣并且仍在不断成长中的社区,并且它也非常适合用来编写那些需要快速运行的服务器端程序。因为Go语言提供了很多过程式编程语言的特性,所以拥有过程式编程语言使用经验的程序员对Go应该都不会感到陌生,但与此同时,Go也提供了函数式编程方面的特性。除了内置对并发编程的支持之外,Go还拥有现代化的包管理系统、垃圾收集特性以及一系列包罗万象、威力强大的标准库。
虽然Go自带的标准库已经非常丰富和宏大了,但Go仍然拥有许多质量上乘的开源库,它们可以对标准库不足的地方进行补充。本书在大部分情况下都会尽可能地使用标准库,但是偶尔也会使用一些第三方的开源库,以此来展示开源社区提供的一些另辟蹊径并且富有创意的想法。
使用Go语言进行Web开发正在变得日益流行,很多公司都已经开始使用Go了:其中包括像Dropbox、SendGrid这样的基础设施公司,像Square和Hailo这样的技术驱动的公司,甚至是BBC、纽约时报这样的传统公司。
在开发大规模Web应用方面,Go提供了一种不同于现有语言和平台但又切实可行的方案。大规模可扩展的Web应用通常需要具备以下特质:
可扩展;
模块化;
可维护;
高性能。
接下来的几个小节将分别对这些特质进行讨论。
1.1.1 Go与可扩展Web应用¶
大规模的Web应用应该是可扩展(scalable)的,这意味着应用的管理者应该能够简单、快速地提升应用的性能以便处理更多请求。如果一个应用是可扩展的,那么它就是线性的,这意味着应用的管理者可以通过添加更多硬件来获得更强的请求处理能力。
有两种方式可以对性能进行扩展:
一种是垂直扩展(vertical scaling),也即是对单台计算机的CPU数量或者性能进行提升;
而另一种则是水平扩展(horizontal scaling),也即是通过增加计算机的数量来提升性能。
因为Go拥有非常优异的并发编程支持,所以它在垂直扩展方面拥有不俗的表现:一个Go Web应用只需要使用一个操作系统线程(OS thread),就可以通过调度来高效地运行数十万个goroutine。
跟其他Web应用一样,Go也可以通过在多个GoWeb应用之上架设代理来进行高效的水平扩展。因为Go Web应用都会被编译为不包含任何动态依赖关系的静态二进制文件,所以我们可以把这些文件分发到没有安装Go的系统里面,从而以一种简单且一致的方式部署Go Web应用。
1.1.2 Go与模块化Web应用¶
大规模Web应用应该由可替换的组件构成,这种做法能够使开发者更容易添加、移除或者修改特性,从而更好地满足程序不断变化的需求。除此之外,这种做法的另一个好处是使开发者可以通过复用模块化的组件来降低软件开发所需的费用。
尽管Go是一门静态类型语言,但用户可以通过它的接口机制对行为进行描述,以此来实现动态类型匹配(dynamic typing)。Go的函数可以接受接口作为参数,这意味着用户只要实现了接口所需的方法,就可以在继续使用现有代码的同时向系统中引入新的代码。与此同时,因为Go的所有类型都实现了空接口,所以用户只需要创建出一个接受空接口作为参数的函数,就可以把任何类型的值用作该函数的实际参数。此外,Go还实现了一些在函数式编程中非常常见的特性,其中包括函数类型、使用函数作为值以及闭包,这些特性允许用户使用已有的函数来构建新的函数,从而帮助用户构建出更为模块化的代码。
Go也经常会被用于创建微服务(microservice)。在微服务架构中,大型应用通常由多个规模较小的独立服务组合而成,这些独立服务通常可以相互替换,并根据它们各自的功能进行组织。比如,日志记录服务会被归类为系统级服务,而开具账单、风险分析这样的服务则会被归类为应用级服务。创建多个规模较小的Go服务并将它们组合为单个Web应用,这种做法使得我们可以在有需要的时候对应用中的服务进行替换,而整个Web应用也会因此变得更加模块化。
1.1.3 Go与可维护的Web应用¶
和其他庞大而复杂的应用一样,拥有一个易于维护的代码库(codebase)对于大规模的Web应用来说也是非常重要的。这是因为大规模的应用通常都会不断地成长和演化,所以开发者需要经常性地回顾并修改代码,而修改难懂、笨拙的代码需要花费大量的时间,并且隐含着可能会造成某些功能无法正常运作的风险。因此,确保源代码能够以适当的方式组织起来并且具有良好的可维护性对开发者来说就显得至关重要了。
Go的设计鼓励良好的软件工程实践,它拥有简洁且极具可读性的语法以及灵活且清晰的包管理系统。除此之外,Go还有一整套优秀的工具,它们不仅可以增强程序员的开发体验,还能够帮助他们写出更具可读性的代码,比如以标准化方式对Go代码进行格式化的源代码格式化程序gofmt就是其中一个例子。
因为Go希望文档可以和代码一同演进,所以它的文档工具godoc会对Go源码及其注释进行语法分析,然后以HTML、纯文本或者其他多种格式创建出相应的文档。godoc的使用方法非常简单,开发者只需要把文档写到源代码里面,godoc就会把这些文档以及与之相关联的代码提取出来,并生成相应的文档文件。
除此之外,Go还内置了对测试的支持:gotest工具会自动寻找与源代码处于同一个包(package)之内的测试代码,并运行其中的功能测试和性能测试。Go也提供了Web应用测试工具,这些工具可以模拟出一个Web服务器,并对该服务器生成的响应(response)进行记录。
1.1.4 Go与高性能Web应用¶
高性能不仅意味着能够在短时间内处理大量请求,还意味着服务器能够快速地对客户端进行响应,并让终端用户(end user)能够快速地执行操作。
Go的一个设计目标就是提供接近于C语言的性能,尽管这个目标目前尚未达成,但Go语言现在的性能已经非常具有竞争力:Go程序会被编译为本地码(native code),这一般意味着Go程序可以运行得比解释型语言的程序要快,并且就像前面说过的那样,Go的goroutine对并发编程提供了非常好的支持,这使得Go应用可以同时处理多个请求。
希望以上介绍能够引起你对使用Go语言及其平台进行Web开发的兴趣。但是在学习如何使用Go进行Web开发之前,我们需要先来了解一下什么是Web应用,以及它们的工作原理是什么,这会给我们学习之后几章的内容带来非常大的帮助。
1.2 Web应用的工作原理¶
如果你在一个技术会议上向在场的程序员们提出“什么是Web应用”这一问题,那么通常会得到五花八门的回答,有些人甚至可能还会因为你问了个如此基础的问题而感到惊讶和不解。通过不同的人对这个问题的不同回答,我们可以了解到人们对于Web应用并没有一个十分明确的定义。比如说,Web服务算不算Web应用?因为Web服务通常会被其他软件调用,而Web应用则是为人类提供服务,所以很多人都认为Web服务与Web应用是两种不同的事物。但如果一个程序能够像RSS feed那样,产生出来的数据既可以被其他软件使用,又可以被人类理解,那么这个程序到底是一个Web服务还是一个Web应用呢?
同样地,如果一个应用只会返回HTML页面,但却并不对页面进行任何处理,那么它是一个Web应用吗?运行在Web浏览器之上的Adobe Flash程序是一个Web应用吗?对于一个纯HTML5编写的应用,如果它运行在一个长期驻留于电脑的浏览器中,那么它算是一个Web应用吗?如果一个应用在向服务器发送请求时没有使用HTTP协议,那么它算是一个Web应用吗?大多数程序员都能够从高层次的角度去理解Web应用是什么,但是一旦我们深入一些,尝试去探究Web应用的实现层次,事情就会变得含糊不清起来。
从纯粹且狭隘的角度来看,Web应用应该是这样的计算机程序:它会对客户端发送的HTTP请求做出响应,并通过HTTP响应将HTML回传至客户端。但这样一来,Web应用不就跟Web服务器一样了吗?的确如此,如果按照上面给出的定义来看,Web服务器和Web应用将没有区别:一个Web服务器就是一个Web应用,如图1-1所示。
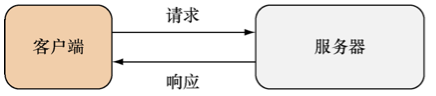
图 1-1 Web 应用最基本的请求与响应结构¶
将Web服务器看作是Web应用的一个问题在于,像httpd和Apache这样的Web服务器都会监视特定的目录,并在接收到请求时返回位于该目录中的文件(比如Apache就会对docroot目录进行监视)。与此相反,Web应用并不会简单地返回文件:它会对请求进行处理,并执行应用程序中预先设定好的操作,如图1-2所示。
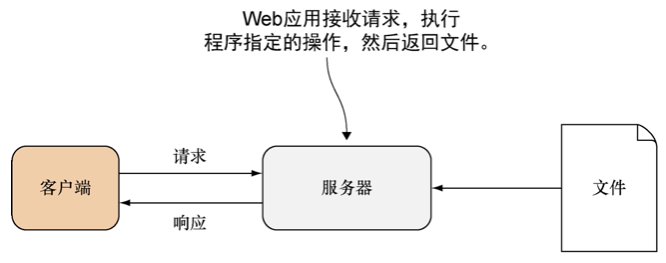
图1-2 Web应用的工作原理¶
从以上观点来看,我们也许可以把Web服务器看作是一种特殊的Web应用,这种应用只会返回被请求的文件。普遍来讲,很多用户都会把使用浏览器作为客户端的应用看作是Web应用。这其中包括Adobe Flash应用、单页Web应用,甚至是那些不使用HTTP协议进行通信但却驻留在桌面或系统上的应用。
为了在书中讨论Web编程的相关技术,我们必须给这些技术一个明确的定义。首先,让我们来给出应用的定义。
应用(application)就是一个与用户进行互动,并帮助用户执行指定活动的软件程序。比如记账系统、人力资源系统、桌面出版软件等,而Web应用则是部署在Web之上,并通过Web来使用的应用。
换句话来说,一个程序只需要满足以下两个条件,我们就可以把它看作是一个Web应用:
这个程序必须向发送命令请求的客户端返回HTML,而客户端则会向用户展示渲染后的HTML;
这个程序在向客户端传送数据时必需使用HTTP协议。
在这个定义的基础上,如果一个程序不是向用户渲染并展示HTML,而是向其他程序返回某种非HTML格式的数据,那么这个程序就是一个为其他程序提供服务的Web服务。本书将在第7章对Web服务进行更详细的说明。
与大部分程序员对Web应用的定义相比,上面给出的定义可能显得稍微狭隘了一些,但因为这个定义消除了所有的模糊与不清晰,并使Web应用变得更加易于理解,所以它对于本书讨论的问题是非常有帮助的。随着读者对本书的不断深入,这一定义将变得更为清晰,但是在此之前,让我们先来回顾一下HTTP协议的发展历程。
1.3 HTTP简介¶
HTTP是万维网的应用层通信协议,Web页面中的所有数据都是通过这个看似简单的文本协议进行传输的。HTTP非常朴素,但是却异常地强大——这个协议自20世纪90年代定义以来,至今只进行了3次迭代修改,其中HTTP 1.1是目前使用最为广泛的一个版本,而最新的一个版本则是HTTP 2.0,又称HTTP/2。
HTTP的最初版本HTTP 0.9是由Tim Berners-Lee创建的,这个简单的协议在当时是为了让万维网能够得以被采纳而创建的:它允许客户端与服务器进行连接,并向服务器发送以空行(CRLF)结尾的ASCII字符串请求,而服务器则会返回不带任何元数据的HTML作为响应。
HTTP 0.9之后的每个新版本实现都包含了大量的新特性,1996年发布的HTTP 1.0就是由大量特性合并而成的,之后的HTTP 1.1版本于1999年发布,而HTTP 2.0版本则于2015年发布。因为目前使用最为广泛的还是HTTP 1.1版本,所以本书主要还是对HTTP 1.1进行讨论,但也会在适当的地方介绍一些HTTP 2.0的相关信息。
首先,让我们通过一个简单的定义来说明什么是HTTP。
备注
HTTP
HTTP是一种无状态、由文本构成的请求-响应(request-response)协议,这种协议使用的是客户端-服务器(client-server)计算模型。
请求-响应是两台计算机进行通信的基本方式,其中一台计算机会向另一台计算机发送请求,而接收到请求的计算机则会对请求进行响应。在客户端-服务器计算模型中,发送请求的一方(客户端)负责向返回响应的一方(服务器)发起会话,而服务器则负责为客户端提供服务。在HTTP协议中,客户端也被称作用户代理(user-agent),而服务器则通常会被称为Web服务器。在大多数情况下,HTTP客户端都是一个Web浏览器。
HTTP是一种无状态协议,它唯一知道的就是客户端会向服务器发送请求,而服务器则会向客户端返回响应,并且后续发生的请求对之前发生过的请求一无所知。相对的,像FTP、Telnet这类面向连接的协议则会在客户端和服务器之间创建一个持续存在的通信通道(其中Telnet在进行通信时使用的也是请求-响应方式以及客户端-服务器计算模型)。顺带一提,HTTP 1.1也可以通过持久化连接来提升性能。
跟很多互联网协议一样,HTTP也是以纯文本方式而不是二进制方式发送和接收协议数据的。这样做是为了让开发者可以在无需使用专门的协议分析工具的情况下,弄清楚通信中正在发生的事情,从而更容易进行故障排查。
因为HTTP最初在设计时只用于传送HTML,所以HTTP 0.9只提供了GET一个方法(method),但新版本对HTTP的扩展使得它逐渐变成了一种通用的协议,用户也得以将其应用于Web应用等分布式系统中,本章接下来就会对Web应用进行介绍。
1.4 Web应用的诞生¶
在万维网出现不久之后,人们开始意识到一点:尽管使用Web服务器处理静态HTML文件这个主意非常棒,但如果HTML里面能够包含动态生成的内容,那么事情将会变得更加有趣。其中,CGI(Common Gateway Interface,通用网关接口)就是在早期尝试动态生成HTML内容的技术之一。
1993年,美国国家超级计算机应用中心(National Center for Supercomputing Applications, NCSA)编写了一个在Web服务器上调用可执行命令行程序的规范(specification),他们把这个规范命名为CGI,并将它包含在了NCSA开发的广受欢迎的HTTPd服务器里面。不过NCSA制定的这个规范最终并没有成为正式的互联网标准,只有CGI这个名字被后来的规范沿用了下来。
CGI是一个简单的接口,它允许Web服务器与一个独立运行于Web服务器进程之外的进程进行对接。通过CGI与服务器进行对接的程序通常被称为CGI程序,这种程序可以使用任何编程语言编写——这也是我们把这种接口称之为“通用”接口的原因,不过早期的CGI程序大多数都是使用Perl编写的。向CGI程序传递输入参数是通过设置环境变量来完成的,CGI程序在运行之后将向标准输出(stand output)返回结果,而服务器则会将这些结果传送至客户端。
与CGI同期出现的还有SSI(server-side includes,服务器端包含)技术,这种技术允许开发者在HTML文件里面包含一些指令(directive):当客户端请求一个HTML文件的时候,服务器在返回这个文件之前,会先执行文件中包含的指令,并将文件中出现指令的位置替换成这些指令的执行结果。SSI最常见的用法是在HTML文件中包含其他被频繁使用的文件,又或者将整个网站都会出现的页面首部(header)以及尾部(footer)的代码段嵌入到HTML文件里面。
作为例子,以下代码演示了如何通过SSI指令,将navbar.shtml文件中的内容包含到HTML文件里面:
<html>
<head><title>Example SSI</title></head>
<body>
<!--#include file="navbar.shtml" -->
</body>
</html>
SSI技术的最终演化结果就是在HTML里面包含更为复杂的代码,并使用更为强大的解释器(interpreter)。这一模式衍生出了PHP、ASP、JSP和ColdFusion等一系列非常成功的引擎,开发者通过使用这些引擎能够开发出各式各样复杂的Web应用。除此之外,这一模式也是Mustache、ERB、Velocity等一系列Web模板引擎的基础。
如前所述,Web应用是为了通过HTTP向用户发送定制的动态内容而诞生的,为了弄明白Web应用的运作原理,我们必须知道HTTP的工作过程,并理解HTTP请求和响应的运作机制。
1.5 HTTP请求¶
HTTP是一门请求-响应协议,协议涉及的所有事情都以一个请求开始。HTTP请求跟其他所有HTTP报文(message)一样,都由一系列文本行组成,这些文本行会按照以下顺序进行排列:
请求行(request-line);
零个或任意多个请求首部(header);
一个空行;
可选的报文主体(body)。
一个典型的HTTP请求看上去将会是这个样子的:
GET /Protocols/rfc2616/rfc2616.html HTTP/1.1
Host: www.w3.org
User-Agent: Mozilla/5.0
(empty line)
这个请求中的第一个文本行就是请求行:
GET /Protocols/rfc2616/rfc2616.html HTTP/1.1
请求行中的第一个单词为请求方法(request method),之后跟着的是URI(Uniform Resource Identifier,统一资源标识符)以及正在使用的HTTP版本。位于请求行之后的两个文本行为请求的首部。注意,这个报文的最后一行为空行,即使报文的主体部分为空,这个空行也必须存在,至于报文是否包含主体则需要根据请求使用的方法而定。
1.5.1 请求方法¶
请求方法是请求行中的第一个单词,它指明了客户端想要对资源执行的操作。HTTP 0.9只有GET一个方法,HTTP 1.0添加了POST方法和HEAD方法,而HTTP 1.1则添加了PUT、DELETE、OPTIONS、TRACE和CONNECT这5个方法,并允许开发者自行添加更多方法——很多人立即就把这个功能付诸实践了。
关于请求方法的一个有趣之处在于,HTTP 1.1要求必须实现的只有GET方法和HEAD方法,而其他方法的实现则是可选的,甚至连POST方法也是可选的。
各个HTTP方法的作用说明如下。
GET——命令服务器返回指定的资源。HEAD——与GET方法的作用类似,唯一的不同在于这个方法不要求服务器返回报文的主体。这个方法通常用于在不获取报文主体的情况下,取得响应的首部。POST——命令服务器将报文主体中的数据传递给URI指定的资源,至于服务器具体会对这些数据执行什么动作则取决于服务器本身。PUT——命令服务器将报文主体中的数据设置为URI指定的资源。如果URI指定的位置上已经有数据存在,那么使用报文主体中的数据去代替已有的数据。如果资源尚未存在,那么在URI指定的位置上新创建一个资源。DELETE——命令服务器删除URI指定的资源。TRACE——命令服务器返回请求本身。通过这个方法,客户端可以知道介于它和服务器之间的其他服务器是如何处理请求的。OPTIONS——命令服务器在一个列表中返回它支持的HTTP方法。CONNECT——命令服务器与客户端建立一个网络连接。这个方法通常用于设置SSL隧道以开启HTTPS功能。PATCH——命令服务器使用报文主体中的数据对URI指定的资源进行修改。
1.5.2 安全的请求方法¶
如果一个HTTP方法只要求服务器提供信息而不会对服务器的状态做任何的修改,那么这个方法就是安全的(safe)。
GET、HEAD、OPTIONS和TRACE都不会对服务器的状态进行修改,所以它们都是安全的方法。
与此相反,
POST、PUT和DELETE都能够对服务器的状态进行修改——比如说,
在处理POST请求时,
服务器存储的数据就可能会发生变化——因此这些方法都不是安全的方法。
1.5.3 幂等的请求方法¶
如果一个HTTP方法在使用相同的数据进行第二次调用的时候,不会对服务器的状态造成任何改变,那么这个方法就是幂等的(idempotent)。根据安全的方法的定义,因为所有安全的方法都不会修改服务器状态,所以它们天生就是幂等的。
PUT和DELETE虽然不安全,但却是幂等的,这是因为它们在进行第二次调用时都不会改变服务器的状态:因为服务器在执行第一个PUT请求之后,URI指定的资源已经被更新或者创建出来了,所以针对同一个资源的第二次PUT请求只会执行服务器已经执行过的动作;与此类似,虽然服务器对于同一个资源的第二次DELETE请求可能会返回一个错误,但这个请求并不会改变服务器的状态。
相反地,因为重复的POST请求是否会改变服务器状态是由服务器自身决定的,所以POST方法既不安全,也非幂等。幂等性是一个非常重要的概念,本书第7章在介绍Web服务时将再次提及这个概念。
1.5.4 浏览器对请求方法的支持¶
GET方法是最基本的HTTP方法,它负责从服务器上获取内容,所有浏览器都支持这个方法。
POST方法从HTML 2.0 开始可以通过添加HTML表单来实现:HTML的form标签有一个名为method的属性,
用户可以通过将这个属性的值设置为get或者post来指定要使用哪种方法。
HTML不支持除GET和POST之外的其他HTTP方法:
在HTML5规范的早期草稿(draft)中,HTML表单的method属性曾经添加过对PUT方法以及DELETE方法的支持,
但这些支持在之后又被删除了。
话虽如此,但流行的浏览器通常都不会只支持HTML一种数据格式——用户可以使用XMLHttpRequest(XHR)来获得对PUT方法以及DELTE方法的支持:
XHR是一系列浏览器API,这些API通常由JavaScript包裹(实际上XHR就是一个名为XMLHttpRequest的浏览器对象)。XHR允许程序员向服务器发送HTTP请求,并且跟“XMLHttpRequest”这个名字所暗示的不一样,这项技术并不仅仅局限于XML格式——包括JSON以及纯文本在内的任何格式的请求和响应,都可以通过XHR进行发送。
1.5.5 请求首部¶
HTTP请求方法定义了发送请求的客户端想要执行的动作,而HTTP请求的首部则记录了与请求本身以及客户端有关的信息。请求的首部由任意多个用冒号分隔的纯文本键值对组成,并在最后使用回车(CR)和换行(LF)作为结尾。
作为HTTP 1.1 RFC的一部分,RFC 7231对主要的一些HTTP请求字段(request field)进行了标准化。过去,非标准的HTTP请求通常以X-作为前缀,但标准并没有沿用这一惯例。
大多数HTTP请求首部都是可选的,宿主(Host)首部字段是HTTP 1.1唯一强制要求的首部。根据请求使用的方法不同,如果请求的报文中包含有可选的主体,那么请求的首部还需要带有内容长度(Content-Length)字段或者传输编码(Transfer-Encoding)字段。表1-1展示了一些常见的请求首部。
表1-1 常见的HTTP请求首部
首部字段 |
作用描述 |
|---|---|
|
客户端在HTTP响应中能够接收的内容类型。
比如说,客户端可以通过 |
|
客户端要求服务器使用的字符集编码。
比如说,客户端可以通过 |
|
这个首部用于向服务器发送基本的身份验证证书 |
|
客户端应该在这个首部中,把服务器之前设置的所有cookie回传给服务器。
打个比方,如果服务器之前在浏览器上设置了3个cookie,
那么Cookie首部字段将在一个字符串里面包含这3个cookie,
并使用分号对这些cookie进行分隔。
以下是一个Cookie首部示例: |
|
请求主体的字节长度 |
|
当请求包含主体的时候,这个首部用于记录主体内容的类型。
在发送 |
|
服务器的名字以及端口号。如果这个首部没有记录服务器的端口号,那么表示服务器使用的是80端口 |
|
发起请求的页面所在的地址 |
|
对发起请求的客户端进行描述 |
1.6 HTTP响应¶
HTTP响应报文是对HTTP请求报文的回复。跟HTTP请求一样,HTTP响应也是由一系列文本行组成,其中包括:
一个状态行;
零个或任意数量的响应首部;
一个空行;
一个可选的报文主体。
也许你已经发现了,HTTP响应的组织方式跟HTTP请求的组织方式是完全相同的。以下是一个典型的HTTP响应的样子(为了节省篇幅,我们省略了报文主体中的部分内容):
200 OK
Date: Sat, 22 Nov 2014 12:58:58 GMT
Server: Apache/2
Last-Modified: Thu, 28 Aug 2014 21:01:33 GMT
Content-Length: 33115
Content-Type: text/html; charset=iso-8859-1
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns='http://www.w3.org/1999/xhtml'> <head><title>Hypertext Transfer Protocol -- HTTP/1.1</title></head><body>...</body></html>
HTTP响应的第一行为状态行,这个文本行包含了状态码(status code)和相应的原因短语(reason phrase),原因短语对状态码进行了简单的描述。除此之外,这个例子中的HTTP响应还包含了一个HTML格式的报文主体。
1.6.1 响应状态码¶
正如之前所说,HTTP响应中的状态码表明了响应所属的类型。HTTP响应状态码共有5种类型,它们分别以不同的数字作为前缀,正如表1-2所示。
表1-2 HTTP响应状态码
状态码类型 |
作用描述 |
|---|---|
1XX |
情报状态码。 服务器通过这些状态码来告知客户端,自己已经接收到了客户端发送的请求,并且已经对请求进行了处理 |
2XX |
成功状态码。这些状态码说明服务器已经接收到了客户端发送的请求,并且已经成功地对请求进行了处理。 这类状态码的标准响应为“200 OK” |
3XX |
重定向状态码。这些状态码表示服务器已经接收到了客户端发送的请求,并且已经对请求进行了处理, 但为了完成请求指定的动作,客户端还需要再做一些其他工作。 这类型的状态码大多数都是用于实现URL重定向的状态码 |
4XX |
客户端错误状态码。这类状态码说明客户端发送的请求出现了某些问题。 在这一类型的状态码中,最常见的就是“404 Not Found”了, 这个状态码表示服务器无法从请求指定的URL中找到客户端想要的资源 |
5XX |
服务器错误状态码。 当服务器因为某些原因而无法正确地处理请求时,服务器就会使用这类状态码来通知客户端。 在这一类状态码中,最常见的就是”500 Internal Server Error”状态码了 |
1.6.2 响应首部¶
响应首部跟请求首部一样,都是由冒号分隔的纯文本键值对组成,并且同样以回车(CR)和换行(LF)结尾。正如请求首部能够告诉服务器更多与请求相关或者与客户端诉求相关的信息一样,响应首部也能够向客户端传达更多与响应相关或者与服务器(对客户端的)诉求相关的信息。表1-3展示了一些常见的响应首部。
表1-3 常见的响应首部
首部字段 |
作用描述 |
|---|---|
|
告知客户端,服务器支持哪些请求方法 |
|
响应主体的字节长度 |
|
如果响应包含可选的主体,那么这个首部记录的就是主体内容的类型 |
|
以格林尼治标准时间(GMT)格式记录的当前时间 |
|
这个首部仅在重定向时使用,它会告知客户端接下来应该向哪个URL发送请求 |
|
返回响应的服务器的域名 |
|
在客户端里面设置一个cookie。
一个响应里面可以包含多个 |
|
服务器通过这个首部来告知客户端,
在 |
1.7 URI¶
Tim Berners-Lee在创建万维网的同时,也引入了使用位置字符串表示互联网资源的概念。他在1994年发表的RFC 1630中对URI(Uniform Resource Identifier,统一资源标识符)进行了定义。在这篇RFC中,他描述了一种使用字符串表示资源名字的方法,以及一种使用字符串表示资源所在位置的方法,其中前一种方法被称为URN(Uniform Resource Name,统一资源名称),而后一种方法则被称为URL(Uniform Resource Location,统一资源定位符)。URI是一个涵盖性术语,它包含了URN和URL,并且这两者也拥有相似的语法和格式。因为本书只会对URL进行讨论,所以书本中提及的URI指代的都是URL。
URI的一般格式为:
<方案名称>:<分层部分>[ ? <查询参数> ] [ # <片段> ]
URI中的方案名称(scheme name)记录了URI正在使用的方案,它定义了URI其余部分的结构。因为URI是一种非常常用的资源标识方式,所以它拥有大量的方案可供使用,不过本书在大多数情况下只会使用HTTP方案。
URI的分层部分(hierarchical part)包含了资源的识别信息,这些信息会以分层的方式进行组织。如果分层部分以双斜线(//)开头,那么说明它包含了可选的用户信息,这些信息将以@符号为结尾,后跟分层路径。不带用户信息的分层部分就是一个单纯的路径,每个路径都由一连串的分段(segment)组成,各个分段之间使用单斜线(/)进行分隔。
在URI的各个部分当中,只有“方案名称”和“分层部分”是必需的。以问号(?)为前缀的查询参数(query)是可选的,这些参数用于包含无法使用分层方式表示的其他信息。多个查询参数会被组织成一连串的键值对,各个键值对之间使用&符号进行分隔。
URI的另一个可选部分为片段(fragment),片段使用井号(#)作为前缀,它可以对URI定义的资源中的次级资源(secondary resource)进行标识。当URI包含查询参数时,URI的片段将被放到查询参数之后。因为URI的片段是由客户端负责处理的,所以Web浏览器在将URI发送给服务器之前,一般都会先把URI中的片段移除掉。如果程序员想要取得URI片段,那么可以通过JavaScript或者某个HTTP客户端库,将URI片段包含在一个GET请求里面。
让我们来看一个使用HTTP方案的URI示例:http://sausheong:password@www.example.com/docs/file?name=sausheong&location=singapore#summary 。
这个URI使用的是http方案,跟在方案名之后的是一个冒号。位于@符号之前的分段sausheong:password记录的是用户名和密码,而跟在用户信息之后的www.example.com/docs/file就是分层部分的其余部分。位于分层部分最高层的是服务器的域名www.example.com,之后跟着的两个层分别为doc和file,每个分层之间都使用单斜线进行分隔。跟在分层部分之后的是以问号(?)为前缀的查询参数,这个部分包含了name=sausheong和location=singapore这两个键值对,键值对之间使用了一个&符号进行连接。最后,这个URI的末尾还带有一个以井号(#)为前缀的片段。
因为每个URL都是一个单独的字符串,所以URL里面是不能够包含空格的。此外,因为问号(?)和井号(#)等符号在URL中具有特殊的含义,所以这些符号是不能够用于其他用途的。为了避开这些限制,我们需要使用URL编码来对这些特殊符号进行转换(URL编码又称百分号编码)。
RFC 3986定义了URL中的保留字符以及非保留字符,所有保留字符都需要进行URL编码:URL编码会把保留字符转换成该字符在ASCII编码中对应的字节值(byte value),接着把这个字节值表示为一个两位长的十六进制数字,最后再在这个十六进制数字的前面加上一个百分比符号(%)。
比如说,
空格在ASCII编码中的字节值为32,
也就是十六进制中的20。
因此,
经过URL编码处理的空格就成了%20,
URL中的所有空格都会被替换成这个值。
比如在接下来展示的这个URL里面,
用户名sau和sheong之间的空格就被替换成了%20:
http://www.example.com/docs/file?name=sau%20sheong&location=singapore 。
1.8 HTTP/2简介¶
HTTP/2是HTTP协议的最新版本,这一版本对性能非常关注。HTTP/2协议由SPDY/2协议改进而来,后者最初是Google公司为了传输Web内容而开发的一种开放的网络协议。
与使用纯文本方式表示的HTTP 1.x不同,HTTP/2是一种二进制协议:二进制表示不仅能够让HTTP/2的语法分析变得更为高效,还能够让协议变得更为紧凑和健壮;但与此同时,对那些习惯了使用HTTP 1.x的开发者来说,他们将无法再通过telnet等应用程序直接发送HTTP报文来进行调试。
跟HTTP 1.x在一个网络连接里面每次只能发送单个请求的做法不同,HTTP/2是完全多路复用的(fully multiplexed),这意味着多个请求和响应可以在同一时间内使用同一个连接。除此之外,HTTP/2还会对首部进行压缩以减少需要传送的数据量,并允许服务器将响应推送(push)至客户端,这些措施都能够有效地提升性能。
因为HTTP的应用范围是如此的广泛,对语法的任何贸然修改都有可能会对已有的Web造成破坏,所以尽管HTTP/2对协议的通信性能进行了优化,但它并没有对HTTP协议本身的语法进行修改:在HTTP/2中,HTTP方法和状态码等功能的语法还是跟HTTP 1.1时一样。
在Go 1.6版本中,
用户在使用HTTPS时将自动使用HTTP/2,
而Go 1.6之前的版本则在golang.org/x/net/http2包里面实现了HTTP/2协议。
本书的第3章将会介绍如何使用HTTP/2。
1.9 Web应用的各个组成部分¶
通过前面的介绍,我们知道了Web应用就是一个执行以下任务的程序:
通过HTTP协议,以HTTP请求报文的形式获取客户端输入;
对HTTP请求报文进行处理,并执行必要的操作;
生成HTML,并以HTTP响应报文的形式将其返回给客户端。
为了完成这些任务,Web应用被分成了处理器(handler)和模板引擎(template engine)这两个部分。
1.9.1 处理器¶
Web应用中的处理器除了要接收和处理客户端发来的请求,还需要调用模板引擎,然后由模板引擎生成HTML并把数据填充至将要回传给客户端的响应报文当中。
用MVC模式来讲,处理器既是控制器(controller),也是模型(model)。在理想的MVC模式实现中,控制器应该是“苗条的”,它应该只包含路由(routing)代码以及HTTP报文的解包和打包逻辑;而模型则应该是“丰满的”,它应该包含应用的逻辑以及数据。
备注
“模型-视图-控制器”模式
模型-视图-控制器(Model-View-Controller,MVC)模式是编写Web应用时常用的模式,这个模式是如此的流行,以至于人们有时候会错误地把这一模式当成了Web应用开发本身。
实际上,MVC模式最初是在20世纪70年代末的施乐帕罗奥多研究中心(Xerox PARC)被引入到Smalltalk语言里面的,这一模式将程序分成了模型、视图和控制器3个部分,其中模型用于表示底层的数据,而视图则以可视化的方式向用户展示模型,至于控制器则会根据用户的输入对模型进行修改。每当模型发生变化时,视图都会自动进行更新,从而展现出模型的最新状态。
尽管MVC模式起源于桌面开发,但它在编写Web应用方面也流行了起来——包括Rubyon Rails、CodeIgniter、Play和Spring MVC在内的很多Web应用框架都把MVC用作它们的基本模式。在这些框架里面,模型一般都会通过结构(struct)或对象(object)被映射(map)到数据库,而视图则会被渲染为HTML,至于控制器则负责对请求进行路由,并管理对模型的访问。
使用MVC框架进行Web应用开发的新手程序员常常会误以为MVC模式就是进行Web应用开发的唯一方法,但Web应用本质上只是一个通过HTTP协议与用户进行互动的程序,只要能够实现这种互动,程序本身可以使用任何一种模式进行开发,甚至不使用模式也是可以的。
为了防止模型变得过于臃肿,并且出于代码复用的需要,开发者有时候会使用服务对象(service object)或者函数(function)对模型进行操作。尽管服务对象严格来说并不是MVC模式的一部分,但是通过把相同的逻辑放置到服务对象里面,并将同一个服务对象应用到不同的模型之上,可以有效地避免在多个模型里面复制相同代码的窘境。
正如之前所说,Web应用并不是一定要用MVC模式进行开发——通过将控制器和模型进行合并,然后由处理器直接执行所有操作并向客户端返回响应的做法不仅是可行的,而且也是十分合理的。
1.9.2 模板引擎¶
通过HTTP响应报文回传给客户端的HTML是由模板(template)转换而成的,模板里面可能会包含HTML,但也可能不会,而模板引擎(template engine)则通过模板和数据来生成最终的HTML。正如之前所说,模板引擎是经由早期的SSI技术演变而来的。
模板可以分为静态模板和动态模板两种,这两种模板都有它们各自的设计哲学。
静态模板是一些夹杂着占位符的HTML,静态模板引擎通过将静态模板中的占位符替换成相应的数据来生成最终的HTML,这种做法和SSI技术的概念非常相似。因为静态模板通常不包含任何逻辑代码,又或者只包含少量逻辑代码,所以这种模板也被称为无逻辑模板。CTemplate和Mustache都属于静态模板引擎。
动态模板除了包含HTML和占位符之外,还包含一些编程语言结构,比如条件语句、迭代语句和变量。JavaServer Pages(JSP)、Active Server Pages(ASP)和Embedded Ruby(ERB)都属于动态模板引擎。PHP刚诞生的时候看上去也像是一种动态模板,它是之后才逐渐演变成一门编程语言的。
到目前为止,本章已经介绍了很多Web应用背后的基础知识以及原理。初看上去,这些内容可能会显得过于琐碎了,但随着读者对本书内容的不断深入,理解这些基础知识的重要性就会慢慢地显现出来。在了解了Web应用开发所需的基本知识之后,现在是时候进入下一个阶段——开始实际地进行Go编程了。在接下里的一节,我们将会开始学习如何使用Go开发Web应用。
1.10 Hello Go¶
在这一节,我们将开始学习如何实际地使用Go构建Web应用。如果你还没有安装Go,那么请先阅读本书的附录,并根据附录中的指示安装Go并设置相关的环境变量。本节在构建Web应用时将会用到Go的net/http包,因为本书将会在接下来的几章中对这个包进行详细的介绍,所以即使你目前对这个包知之甚少,也不必过于担心。目前来说,你只需要在电脑上键入本节展示的代码,编译它,然后观察这些代码是如何运行的就可以了。习惯了使用大小写无关编程语言的读者请注意,因为Go语言是区分大小写的,所以在键入书本展示的代码时请务必注意代码的大小写。
本书展示的所有代码都可以在这个GitHub页面找到: https://github.com/sausheong/gwp 。
请在你的工作空间的src目录中创建一个first_webapp子目录,并在这个子目录里面创建一个server.go文件,然后将代码清单1-1中展示的源代码键入到文件里面。
代码清单1-1 使用Go构建的Hello World Web应用
package main
import (
"fmt"
"net/http"
)
func handler(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Hello World, %s!", request.URL.Path[1:])
}
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
在一切就绪之后,请打开你的终端,执行以下命令:
$ go install first_webapp
你可以在任意目录中执行这个命令。
在正确地设置了GOPATH环境变量的情况下,这个命令将在你的$GOPATH/bin目录中创建一个名为first_webapp的二进制可执行文件,接着就可以在终端里面运行这个文件了。如果你按照附录的指示,将$GOPATH/bin目录也添加到了PATH环境变量当中,那么你也可以在任意目录中执行first_webapp文件。被执行的first_webapp文件将在系统的8080端口上启动你的Web应用,一切就这么简单!
现在,打开网页浏览器并访问 http://localhost:8080/ 。如果一切正常,那么你将会看到图1-3所示的内容。
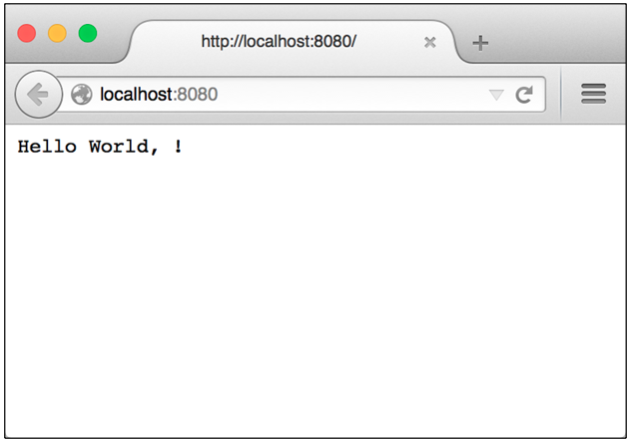
图1-3 我们创建的首个Web应用¶
让我们来仔细地分析一下这个Web应用的代码。
第一行代码声明了这个程序所属的包,
跟在package关键字之后的main就是包的名字。
Go语言要求可执行程序必须位于main包当中,Web应用也不例外。
如果你曾经使用过Ruby、Python或者Java等其他编程语言来开发Web应用,
那么你可能已经发现了Go和这些语言之间的区别:
其他语言通常需要将Web应用部署到应用服务器上面,
并由应用服务器为Web应用提供运行环境;
但是对于Go来说,
Web应用的运行环境是由net/http包直接提供的,
这个包和应用的源码会一起被编译成一个可以快速部署的独立Web应用。
位于package语句之后的import语句用于导入所需的包:
import (
"fmt"
"net/http"
)
被导入的包分别为fmt包和http包,
前者使得程序可以使用Fprintf等函数对I/O进行格式化,
而后者则使得程序可以与HTTP进行交互。
顺带一提,
Go的import语句不仅可以导入标准库里面的包,
还可以从第三方库里面导入包。
出现在导入语句之后的是一个函数定义:
func handler(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Hello World, %s!", request.URL.Path[1:])
}
这3行代码定义了一个名为handler的函数。
处理器(handler)这个名字通常用来表示在指定事件被触发之后,
负责对事件进行处理的回调函数,
这也正是我们如此命名这个函数的原因
(不过从技术上来说,至少在Go里面,这个函数并不是一个处理器,而是一个处理器函数,处理器和处理器函数之间的区别将在第3章进行介绍)。
这个处理器函数接受两个参数作为输入,
第一个参数为ResponseWriter接口,而第二个参数则为指向Request结构的指针。
handler函数会从Request结构中提取相关的信息,
然后创建一个HTTP响应,
最后再通过ResponseWriter接口将响应返回给客户端。
至于handler函数内部的Fprintf函数在被调用时则会使用一个ResponseWriter接口、一个带有单个格式化指示符(%s)的格式化字符串以及从Request结构里面提取到的路径信息作为参数。
因为我们之前访问的地址为http://localhost:8080/ ,
所以应用并没有打印出任何路径信息,
但如果我们访问地址http://localhost:8080/sausheong/was/here ,
那么浏览器应该会展示出图1-4所示的信息。
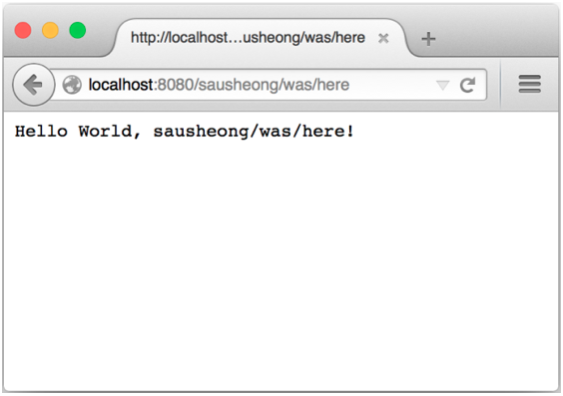
图1-4 带有路径信息的Hello World示例¶
Go语言规定,
每个需要被编译为二进制可执行文件的程序都必须包含一个main函数,
用作程序执行时的起点:
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
这个main函数的作用非常直观,
它首先把之前定义的handler函数设置成根(root)URL(/)被访问时的处理器,
然后启动服务器并让它监听系统的8080端口(按下Ctrl+C可以停止这个服务器)。
至此,这个使用Go编写的Hello World Web应用就算顺利完成了。
本章以介绍Web应用的基础知识开始, 并最终走马观花地编写了一个简单却没什么用处的Go Web应用作为结束。 在接下来的一章, 我们将会看到更多代码, 并学习如何使用Go以及它的标准库去编写更真实的Web应用(不过这些应用距离真正生产级别的应用还有一定距离)。 尽管第2章出现的大量代码可能会让读者有一种囫囵吞枣的感觉, 但我们将会从中学习到一个典型的Go Web应用是如何进行组织的。
1.11 小结¶
使用Go开发的Web应用不仅具有可扩展、模块化和可维护等特性,并且使用Go还能够更容易地开发出性能更高的应用,因此Go是一门非常适合进行Web开发的编程语言。
因为Web应用是一种通过HTTP协议向客户端返回HTML的程序,所以理解HTTP协议对于学习Web应用开发来说是相当重要的。
HTTP是一种简单、无状态、纯文本的客户端-服务器协议,它被用于在客户端和服务器之间进行数据交换。
HTTP的请求和响应都以相同的格式进行组织——它们首先以一个请求行或者响应行作为开始,接着后跟一个或多个首部,最后还有一个可选的主体。
每个HTTP请求都有一个请求行,请求行里面包含了一个HTTP方法,HTTP方法标示了请求想要让服务器执行的动作。
GET方法和POST方法是最常用的两个HTTP方法。每个HTTP响应都有一个响应行,响应行会告知客户端请求的执行状态。
任何Web应用都包含处理器和模板引擎,这两个主要部分分别与HTTP协议的请求和响应相对应。
处理器负责接收HTTP请求并处理它们。
模板引擎负责生成HTML,这些HTML之后会作为HTTP响应的其中一部分被回传至客户端。